A bank is interested in identifying different attributes of its customers and below is the sample data of 150 customers. In the data table for the dummy variable Gender, 0 represents Male and 1 represents Female. And for the dummy variable Personal loan, 0 represents a customer who has not taken personal loan and 1 represents a customer who has taken personal loan.
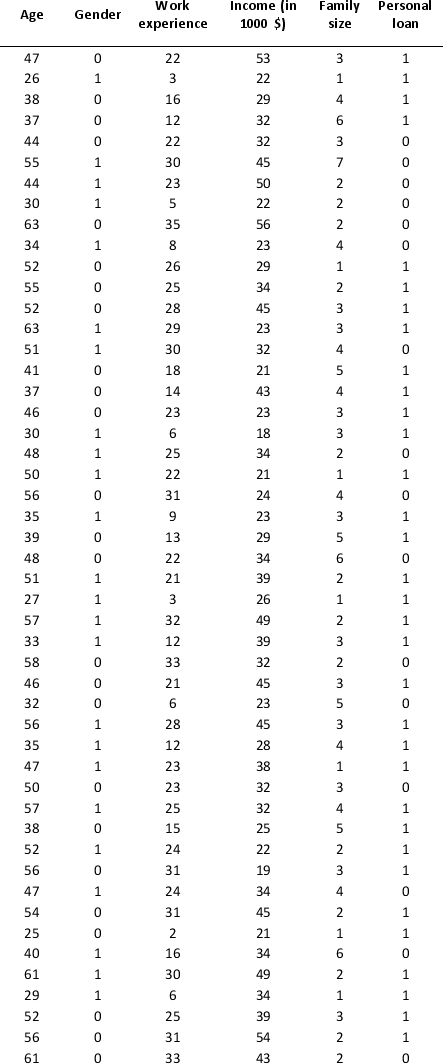
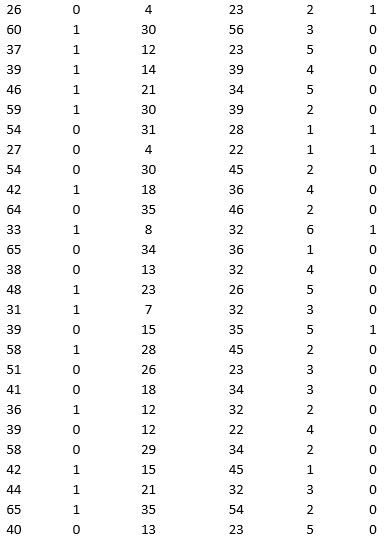
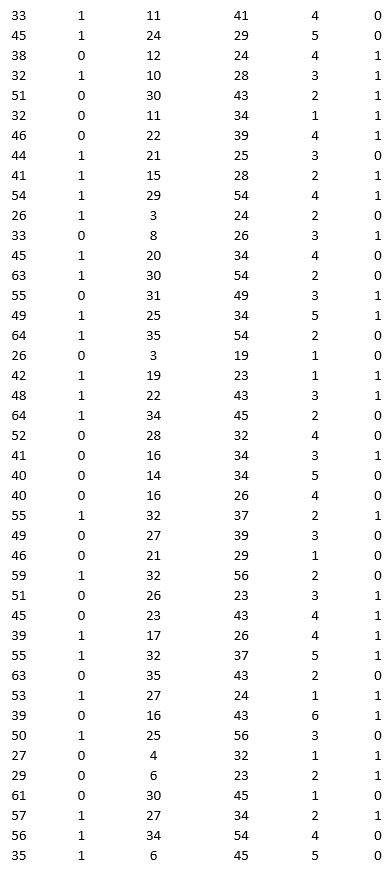
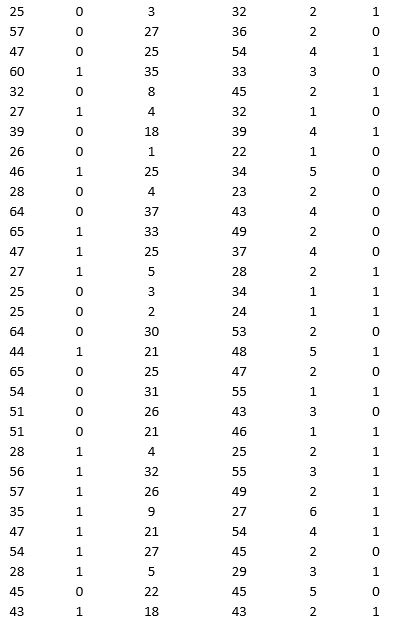
Partition the data into training (50 percent), validation (30 percent), and test (20 percent) sets. Classify the data using k-nearest neighbors with up to k = 10. Use Age, Gender, Work experience, Income (in 1000 $), and Family size as input variables and Personal loan as the output variable. In Step 2 of XLMiner's k-nearest neighbors Classification procedure, be sure to Normalize input data and to Score on best k between 1 and specified value. Generate lift charts for both the validation data and test data.
a. For the cutoff probability value 0.5, what value of k minimizes the overall error rate on the validation data? Explain the difference in the overall error rate on the training, validation, and test data.
b. Examine the decile-wise lift chart on the test data. Identify and interpret the first decile lift.
c. For cutoff probability values of 0.5, 0.4, 0.3, and 0.2, what are the corresponding Class 1 error rates and Class 0 error rates on the validation data?
Definitions:
Depression
A common but serious mood disorder that causes severe symptoms affecting how you feel, think, and manage daily activities.
Heart Disease
A range of conditions that affect the heart, including coronary artery disease, arrhythmias, and congenital heart defects.
Stress and Health
The relationship between psychological stress and its effects on an individual's physical and mental well-being.
Cold Virus
A virus that causes the common cold, leading to symptoms like nasal congestion, cough, and sore throat.
Q1: The _ option is helpful when the
Q3: Which of the following is a preventable
Q5: Penile carcinomas tend to metastasize first to
Q8: A _ classifies a categorical outcome variable
Q10: Which of the following nonneoplastic breast lesions
Q16: The lift ratio of an association rule
Q16: The supervisor of a production company is
Q36: In the Bass forecasting model, parameter m:<br>A)
Q44: _ is a measure of the heterogeneity
Q52: The exponential smoothing forecast for period t