A research team wanted to assess the relationship between age, systolic blood pressure, smoking, and risk of stroke. A sample of 150 patients who had a stroke is selected and the data collected are given below. Here, for the variable Smoker, 1 represents smokers and 0 represents nonsmokers.
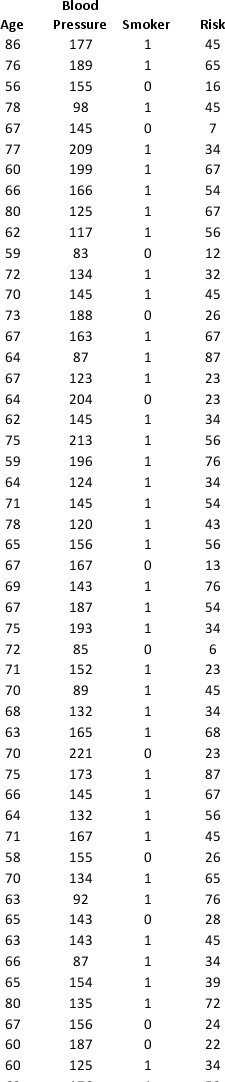
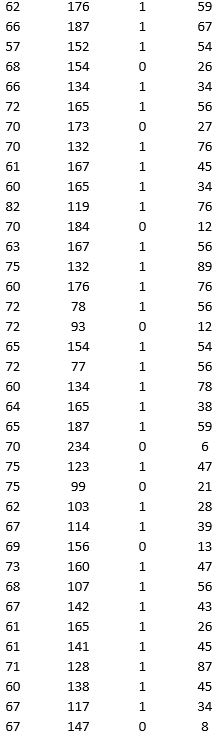
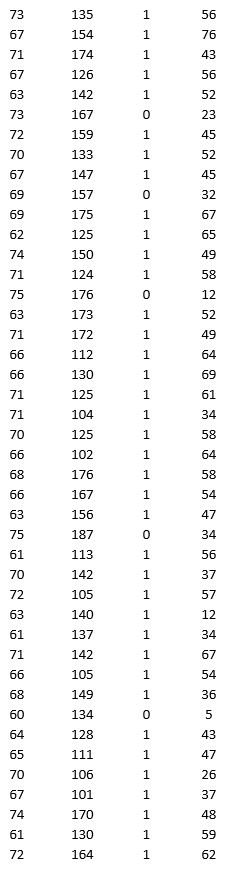
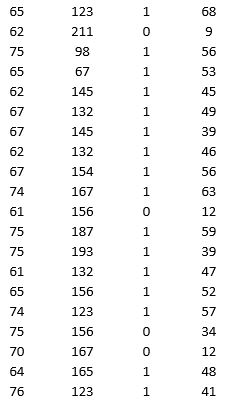
Partition the data into training (50 percent), validation (30 percent), and test (20 percent) sets. Predict the Risk of stroke using k-nearest neighbors with up to k = 20. Use Risk as the output variable and all the other variables as input variables. In Step 2 of XLMiner's k-Nearest Neighbors Prediction procedure, be sure to Normalize input data and to Score on best k between 1 and specified value. Generate a Detailed Scoring report for all three sets of data.
a. What value of k minimizes the root mean squared error (RMSE) on the validation data?
b. What is the RMSE on the validation data and test data?
c. What is the average error on the validation data and test data? What does this suggest?
Definitions:
Autopsy
A post-mortem examination to discover the cause of death or the extent of disease.
Research Design
A structured plan that outlines how a study will be conducted to investigate a particular problem or hypothesis.
Quasi-Experiment
An empirical study that appears to involve some, but incomplete, experimental control (e.g., through nonrandom assignment of participants to conditions).
Clinical Interview
A research paradigm in which an investigator begins by asking participants a series of open-ended questions but follows up on the responses with specific questions that have been prepared in advance.
Q3: Which of the following is a drug
Q4: A 20-year-old man is being treated for
Q15: A disadvantage of the simple what-if analyses
Q29: The process of evaluating a decision in
Q34: No more than one state of nature
Q39: We create multiple dashboards<br>A) to help the
Q42: Consider the below table and the line
Q44: A summary of data that shows the
Q47: What do nodes in an influence diagram
Q48: Jim is trying to solve a problem