A bank wants to understand better the details of customers who are likely to default the loan. In order to analyze this, the data from a random sample of 200 customers are given below:
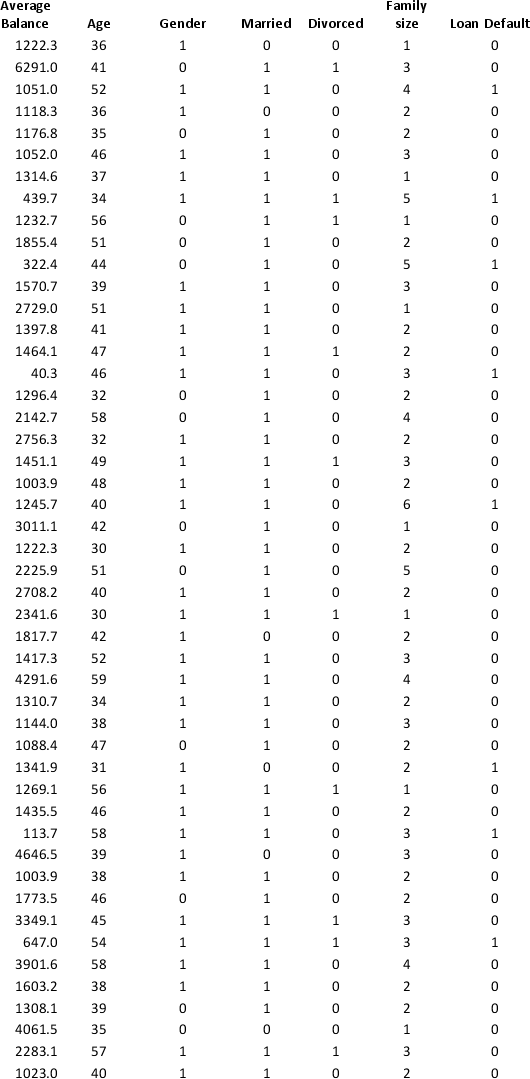
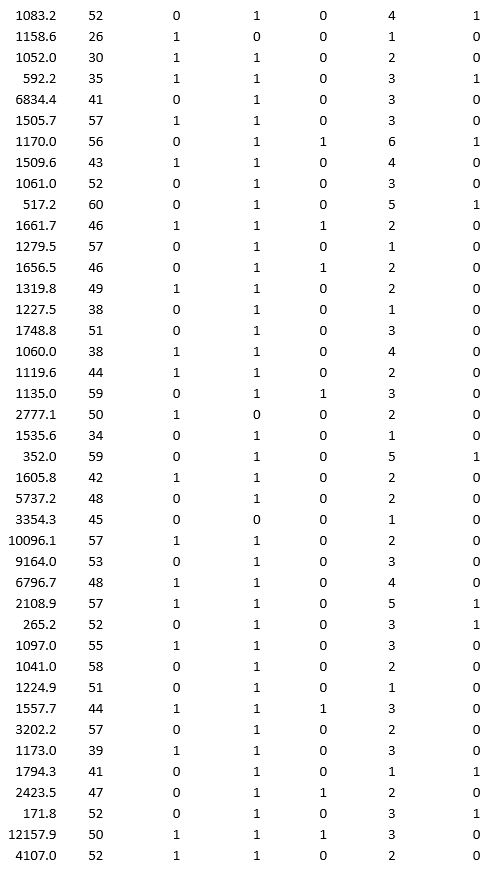
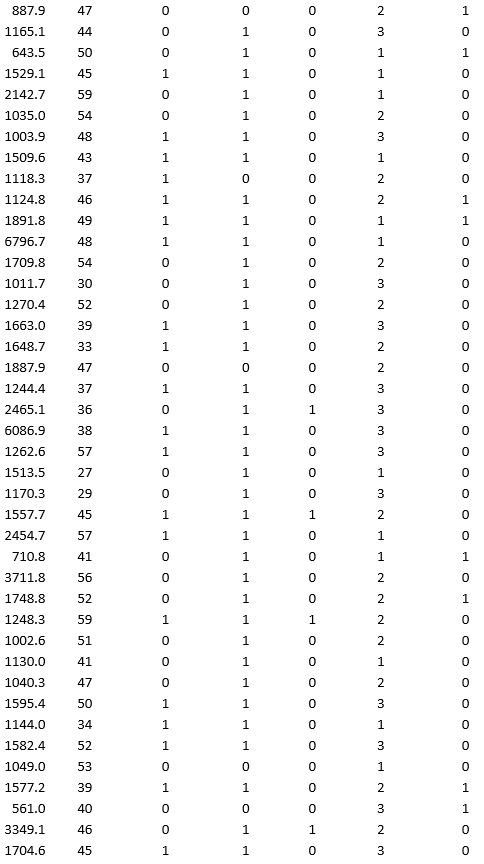
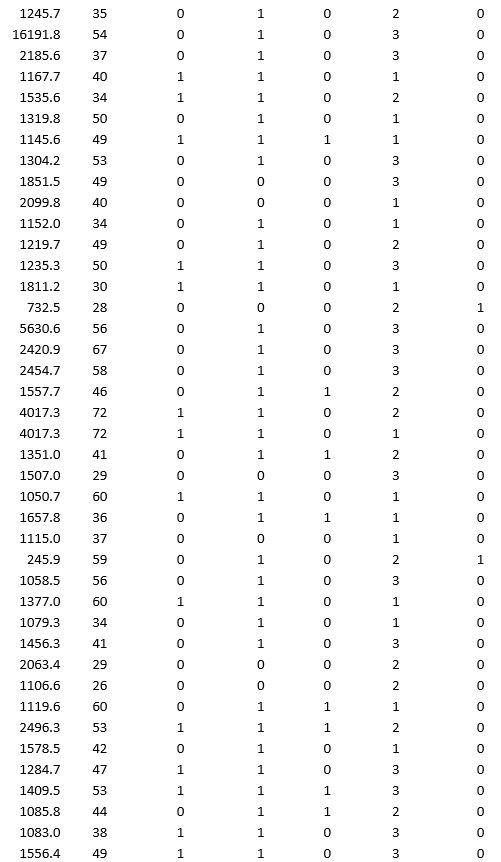
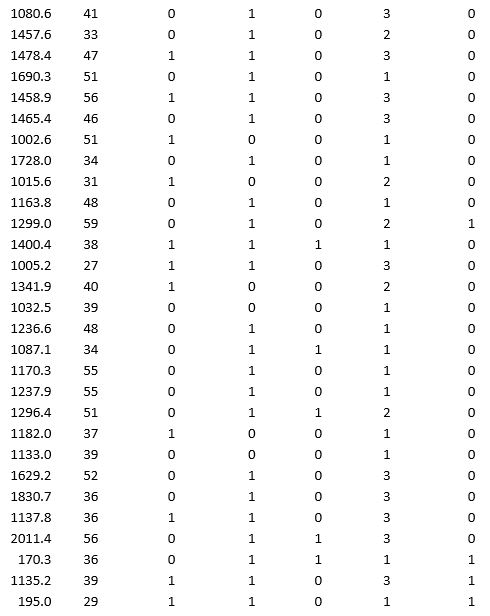
In XLMiner's Partition with Oversampling procedure, partition the data so there is 50 percent successes (Loan default) in the training set and 40 percent of the validation data is taken away as test data. Classify the data using k-nearest neighbors with up to k = 10. Use Loan default as the output variable and all the other variables as input variables. In Step 2 of XLMiner's k-nearest neighbors Classification procedure, be sure to Normalize input data and to Score on best k between 1 and specified value. Generate lift charts for both the validation data and test data.
a. For the cutoff probability value 0.5, what value of k minimizes the overall error rate on the validation data?
b. What is the overall error rate on the test data? Interpret this measure.
c. What are the Class 1 error rate and the Class 0 error rate on the test data?
d. Compute and interpret the sensitivity and specificity for the test data.
e. Examine the decile-wise lift chart on the test data. What is the first decile lift on the test data? Interpret this value.
Definitions:
Working Capital
The variance between a business's present assets and its present debts, which demonstrates the firm's liquidity.
Common Stock
A type of equity security that represents ownership in a corporation, with rights to vote on corporate matters and receive dividends.
Market Price
The existing rate for buying or selling a product or service in a market environment.
Working Capital
The difference between a company's current assets and current liabilities, indicating the short-term financial health.
Q3: Which of the following is the most
Q6: Arterial hypertension of Cushing syndrome is associated
Q6: Which of the following drugs causes microvesicular
Q7: The nurse talks with a clinic patient
Q15: Crohn disease is most often diagnosed in
Q25: Data-ink is the ink used in a
Q30: The nurse is planning the teaching/learning objectives
Q42: The _ value for each less-than-or-equal-to constraint
Q43: A crosstabulation in Microsoft Excel is known
Q56: Which of the following conclusions can be