Instruction 12-11
A computer software developer would like to use the number of downloads (in thousands)for the trial version of his new shareware to predict the amount of revenue (in thousands of dollars)he can make on the full version of the new shareware.Following is the output from a simple linear regression along with the residual plot and normal probability plot obtained from a data set of 30 different sharewares that he has developed:
ANOVA
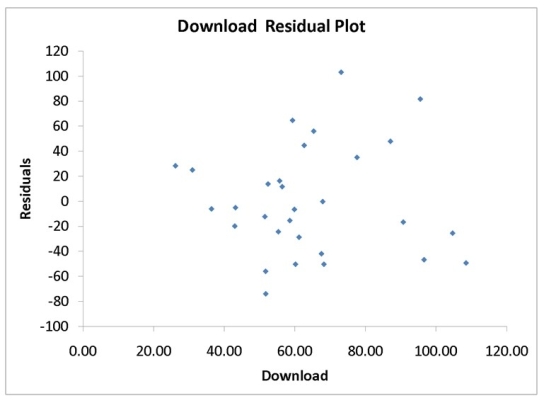
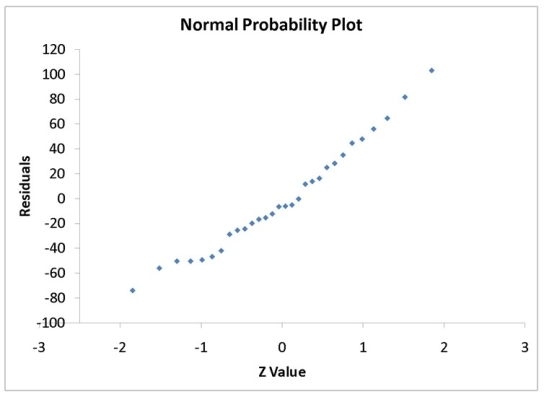
-Referring to Instruction 12-11,the normality of error assumption appears to have been violated.
Definitions:
Source System
A system where data originates before it is transferred to a destination system, commonly used in data integration and migration scenarios.
Data Warehouse
A large store of data accumulated from a wide range of sources within a company and used to guide management decisions.
ERP
Enterprise Resource Planning, a type of software that organizations use to manage day-to-day business activities such as accounting, procurement, project management, risk management, compliance, and supply chain operations.
Big Data
The collection and analysis of large and complex data sets that traditional data-processing application software are inadequate to deal with.
Q15: Referring to Instruction 14-17,set up a scatter
Q60: Referring to Instruction 11-8,the amount of total
Q94: In selecting an appropriate forecasting model,which of
Q126: Referring to Instruction 10-2,the researcher was attempting
Q138: Referring to Instruction 11-10,the value of the
Q140: Referring to Instruction 10-11,the p-value of the
Q154: Referring to Instruction 12-1,interpret the estimate of
Q160: Referring to Instruction 10-6,what is the 95%
Q194: Referring to Instruction 12-9,the degrees of freedom
Q249: Referring to Instruction 13-14,the Head of Department